- Podatkovna zbirka SloREL kot nova priložnost za razvoj jezikovnih tehnologij
Novice
Prepoznavanje odnosov med poimenovanimi enotami je pomembna naloga pri obdelavi besedil, saj omogoča razumevanje povezav med različnimi pojmi. Takšne informacije so ključne za delovanje iskalnikov in digitalnih pomočnikov. Medtem ko za angleščino obstaja veliko virov in orodij, so manjši jeziki, kot je slovenščina, na tem področju precej zapostavljeni.
Tega izziva so se v znanstvenem članku Semi-Supervised Relation Extraction Corpus Construction and Models Creation for Under-Resourced Languages: A Use Case for Slovene, objavljenem v reviji Information, lotili mladi raziskovalec Timotej Knez (UL FRI), izr. prof. dr. Slavko Žitnik (UL FRI) ter Miha Štravs. V prispevku so predstavili polavtomatsko ustvarjeno slovensko podatkovno zbirko za prepoznavanje relacij, imenovano SloREL.
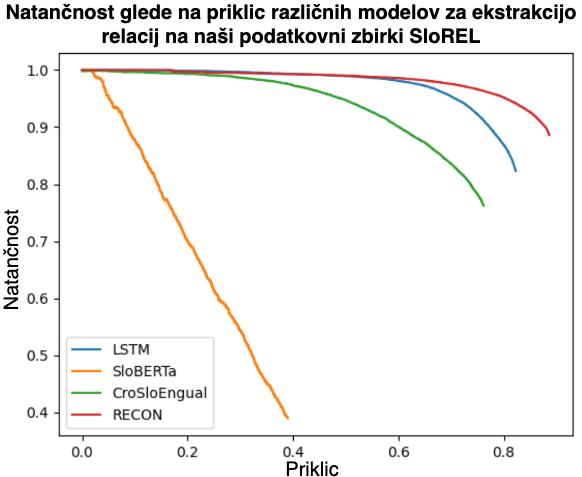
Zbirka vsebuje dokumente iz Wikipedije z označenimi poimenovanimi enotami (entitetami) in njihovimi odnosi (relacijami), pridobljenimi s pomočjo grafa znanja WikiData. Na tej osnovi so avtorji trenirali več modelov za prepoznavanje odnosov in dosegli rezultate, primerljive z angleškimi podatki. Z razvojem zbirke SloREL in predstavitvijo polavtomatskega pristopa so pomembno prispevali k razvoju tehnologij za slovenščino ter pokazali, da je pristop mogoče razširiti tudi na druge jezike. Podatkovna zbirka je javno dostopna na repozitoriju CLARIN.SI.

Celoten članek si lahko preberete na povezavi: Knez, T., Štravs, M., & Žitnik, S. (2025). Semi-Supervised Relation Extraction Corpus Construction and Models Creation for Under-Resourced Languages: A Use Case for Slovene. Information, 16(2), 143.